
Now in its third year, Azavea’s Summer of Maps Program has become an important resource for non-profits and student GIS analysts alike. Non-profits receive pro bono spatial analysis work that can enhance their business decision-making processes and programmatic activities, while students benefit from Azavea mentors’ experience and expertise. This year, three fellows worked on projects for six organizations that spanned a variety of topics and geographic regions. This blog series documents some of their accomplishments and challenges during their fellowship. Our 2014 sponsors, Google, Esri and PennDesign helped make this program possible. For more information about the program, please fill out the form on the Summer of Maps website.
One of my two projects this summer as a fellow here at Azavea was working with CBEI, the Consortium for Building Energy Innovation, located here in Philadelphia. CBEI had an interest in understanding a national view on building energy use and the potentials for reducing energy consumption in five cities: Philadelphia, Washington, D.C., New York City, Minneapolis, and San Francisco. Over the last few years, cities and states have passed benchmarking and disclosure laws that require the owners of buildings – commercial, municipal, private, public, and non-residential – to report their annual energy use. Due to this recent wave of published data, the potential now exists for a comprehensive analysis across many cities. This project is certainly one of the first of its kind, since the data were so recently published, and it has already garnered interest from various city governments who are interested in learning of the results and the processes utilized throughout the project.
Comparing five cities is not always an easy task, however. Each of the five cities that we investigated for this project are located in different parts of the U.S., have different sizes, and have a different amount of census tracts – a common subdivision of a county with a population size between 1,200 and 8,000 people, generally. Most importantly, the benchmarked building stock for each city was not the same. While we initially embarked on the project with the goal of mapping benchmarked commercial buildings, we were only able to find one published data set for this type, simply because they have not yet been made public. See the following table for a description of which type of building stock we analyzed for each city:
| City Name | Type of Buildings (number) |
| Philadelphia | Commercial (1,171) |
| New York City | Non-Residential (2,240) |
| Washington, D.C. | Private (490) |
| Minneapolis | Public (101) |
| San Francisco | Municipal (431) |
Although there existed some overlap in the types of buildings analyzed for each city, is important to take note that each city published a different set of data that otherwise might not have been compared, if more data had been available. Additionally, the data sets were self-reported by the buildings involved, which is an indicator that errors may – and do – exist. Nonetheless, we set forth to break down each city’s building stock by five key variables related to energy efficiency: greenhouse gas (GHG) emissions, weather normalized source energy use intensity (EUI), ENERGY STAR score, building size, and year built. We chose these five variables because we found them to be good representations of energy efficiency and they were largely available for each of the five cities – with the exception of year built for NYC. Mapping each city individually was simple and informative. We generated one map per variable, per city, such as the one below.
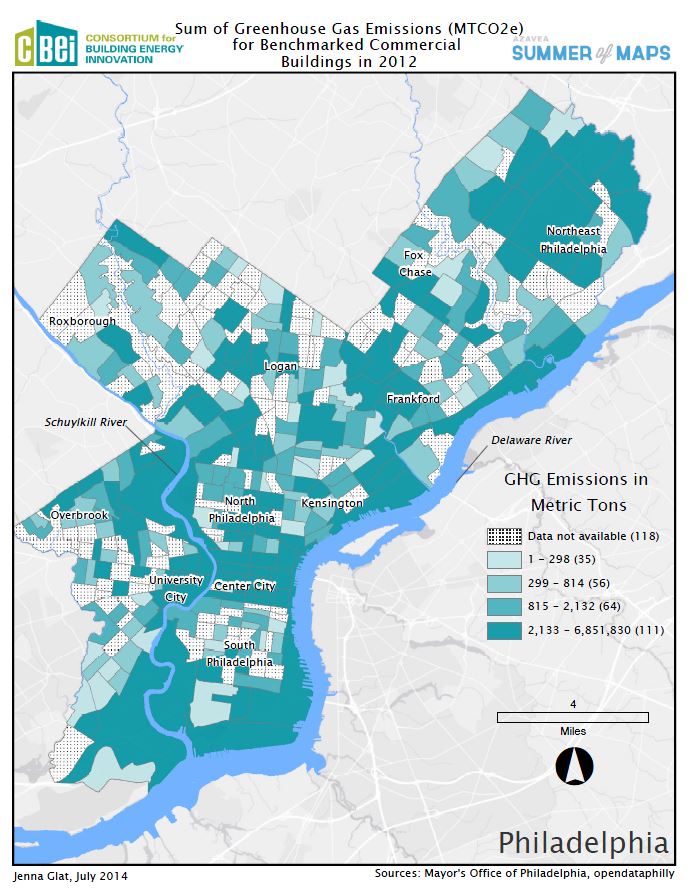{kind=link}
As part of our analysis we wanted to create composite maps of both the cities and the variables in order to more directly compare and contrast. When it came the time to place 5 cities, showing the same variable, on the map, we noticed one major flaw: that the legend values were totally different, because they were each representing their own city, and therefore the highest category of values for one city could fall in the middle of the range for a different city. In order to correct this problem, we created an excel spreadsheet with every city’s values for each variable, and used the quantile tool to correctly distribute the values, accounting for each city. Quantiles are a great way to represent a dataset, because rather than dividing the data by arbitrary intervals, it separates the data by 25%: 0-25%, 25-50%, 50-75%, 75-100%. I initially thought that this method would not be a good way to represent the data, as some of the highest values for particular cities are so much larger than the highest values of a smaller city, like Minneapolis, but because quantiles use percentages and not intervals, it turned out to be a great way to display the data accurately.
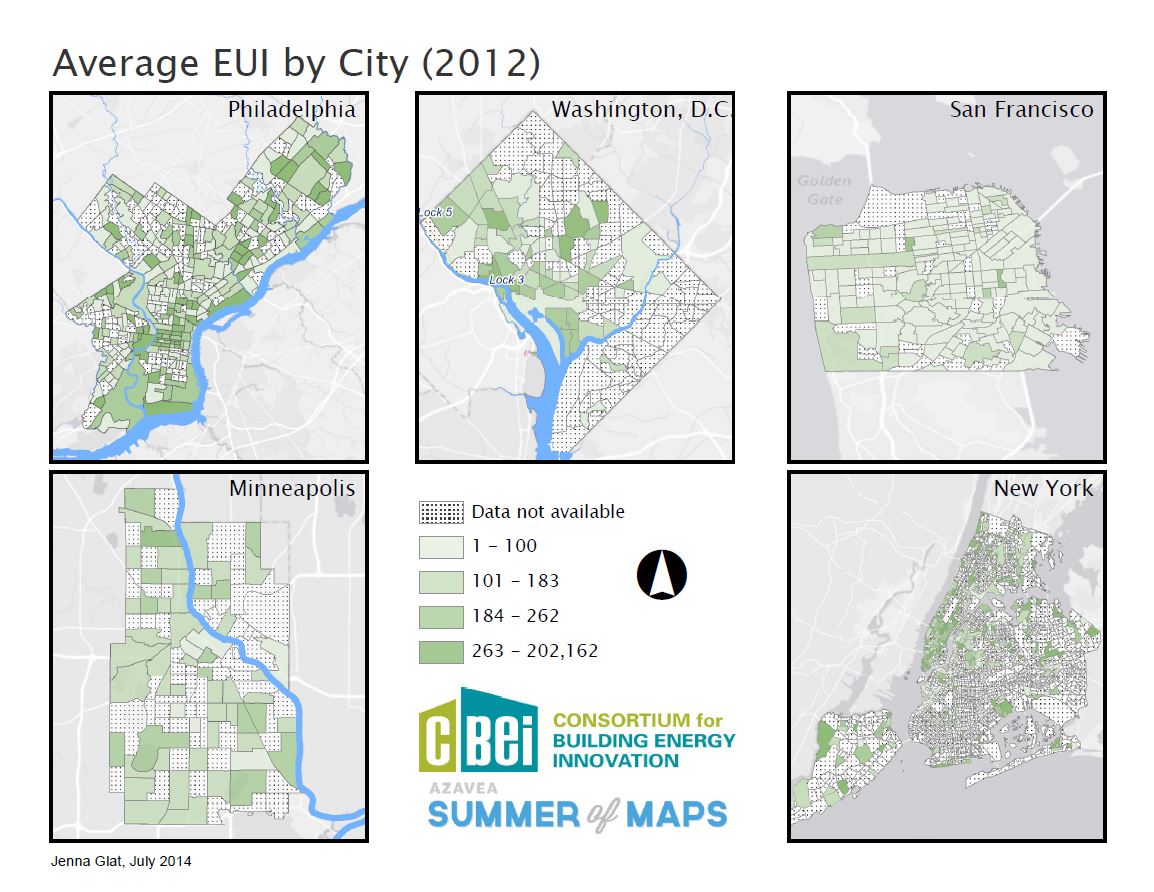{kind=link}
While it can be tricky to display cities of different sizes, showing slightly different information, on one map, it is worth the effort to normalize all of the data in order to accurately make comparisons. It can be truly fascinating to see how two cities, thousands of miles apart, relate in terms of energy efficiency – how they are similar and how they are different. I hope that this project will lead to similar initiatives in the future to improve energy efficiency and reduce costs, especially as more data sets become benchmarked and released to the public.