
A responsive app should always be ready to respond to the user, regardless of any background processing that may be happening. This is especially true for geoprocessing applications which often entail long-running processes. To keep the app responsive, the thread that processes user interaction must always be ready to respond, and never be blocked. To keep the app available, the thread that handles web requests must always have the capacity for new requests. We don’t want an application that is blocked on every request, like this:

This may be alleviated by applying Asynchrony: the technique of passing the information for a long, complex computation to a second execution context, to either be alerted on completion (using a callback) or by repeatedly checking for updates (using polling) for a finite number of times.
Asynchrony within a platform is best expressed in terms of callbacks or promises. Asynchrony between platforms is easiest expressed in terms of polling. A complex web application with heavy front-end and back-end codebases requires both. In this blog post we give an overview of the various ways asynchrony was used in a project we worked on with Stroud Water Research Center: Model My Watershed.
For example, when a user selects an area of interest and triggers an analysis, they are shown a spinner indicating a task running in the background, while they remain free to interact with the rest of the app:
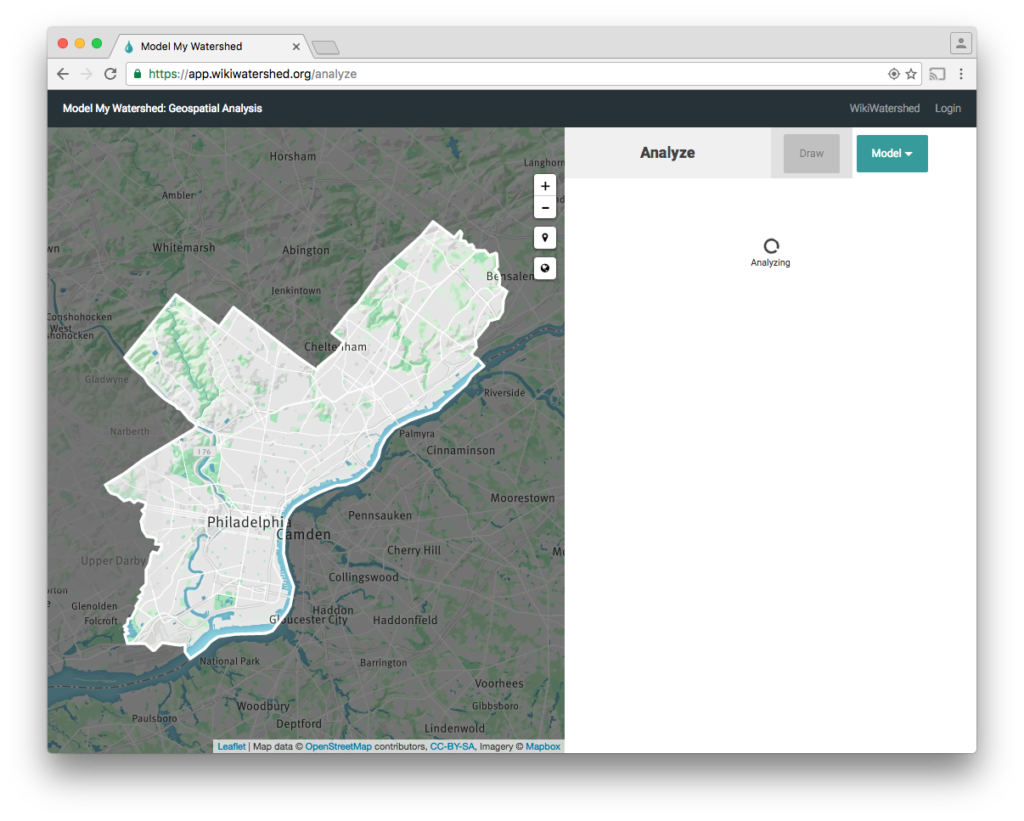
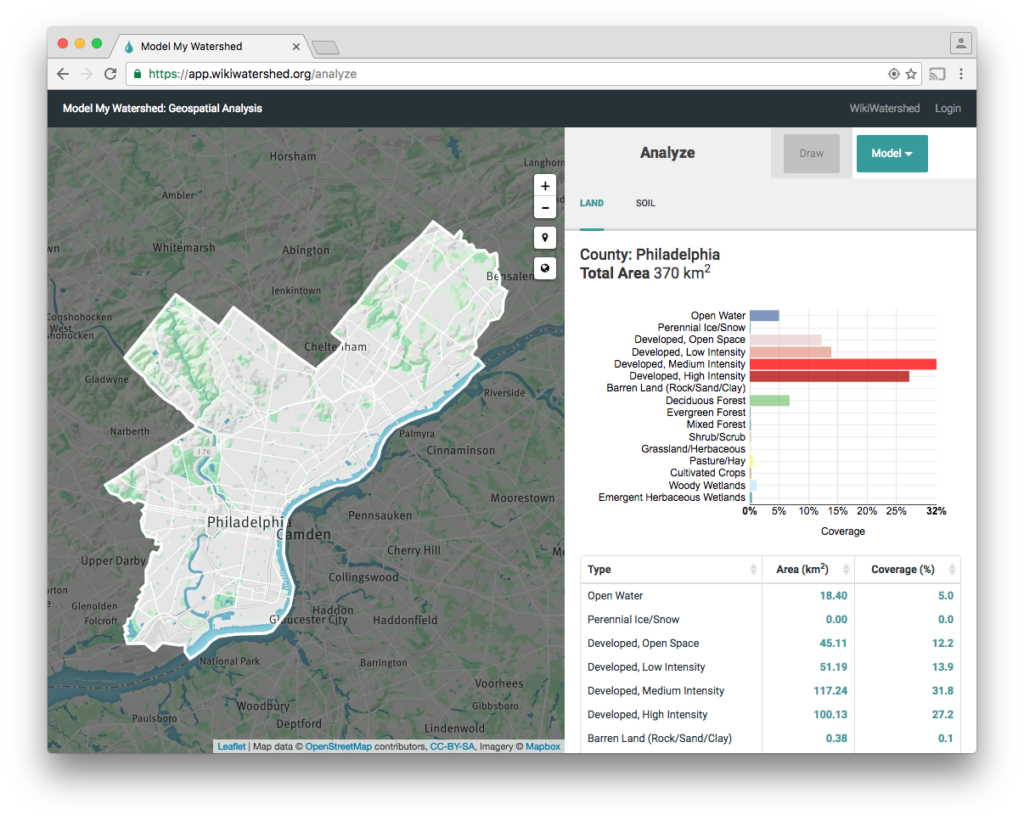
In the case above, we POST a GeoJSON representation of the area of interest to a server endpoint that gives us back a job id, which is then used to poll for results. When results return successfully, they are rendered thus:
JavaScript Asynchrony on the Front-End
The process from the client side looks like this:
- Send the server a GeoJSON representation of the area of interest, to receive a job id
- Poll for given job id …
- … until actual results are received, at which point display them on screen
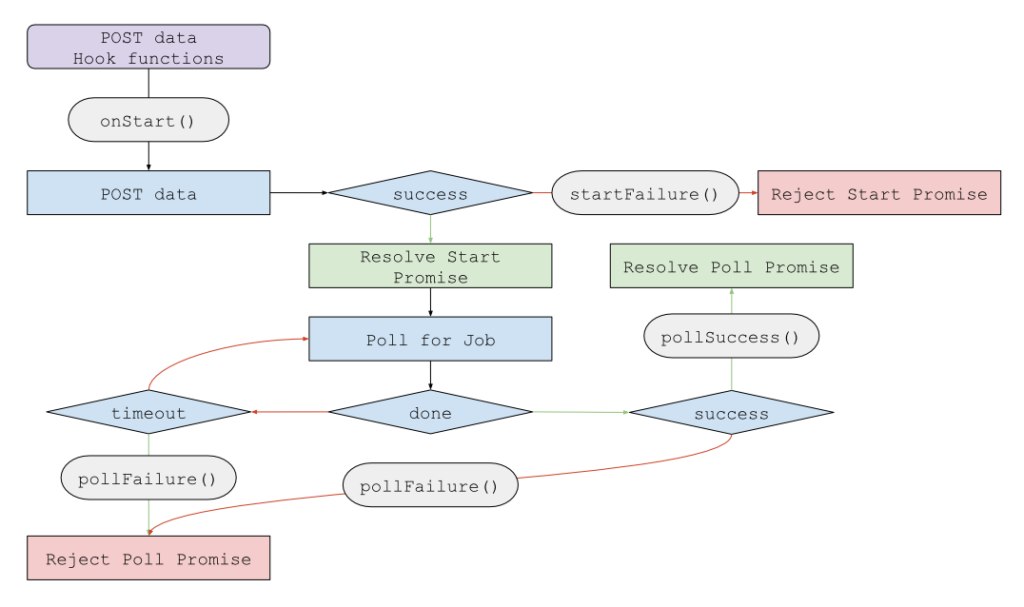
Since the app includes multiple stages that require such treatment, we abstracted out the front-end functionality into a reusable Backbone model called TaskModel. It is instantiated with a taskHelper object containing data for POSTing as well as a number of hook methods to be called at various stages of polling. First, the initial data is POSTed. Then we begin polling for the given job id, which we continue until we have results or a timeout occurs. The hook methods supplied by the caller are called at various stages as shown in the diagram. Furthermore, the startPromise and pollPromise can be handled by multiple listeners, allowing a number of Backbone views and models to be notified of updates. This is shown in the following diagram:
The TaskModel is generic enough that it can is reused for a number of different interactions, including analyzing areas of interest and running geoprocessing models.
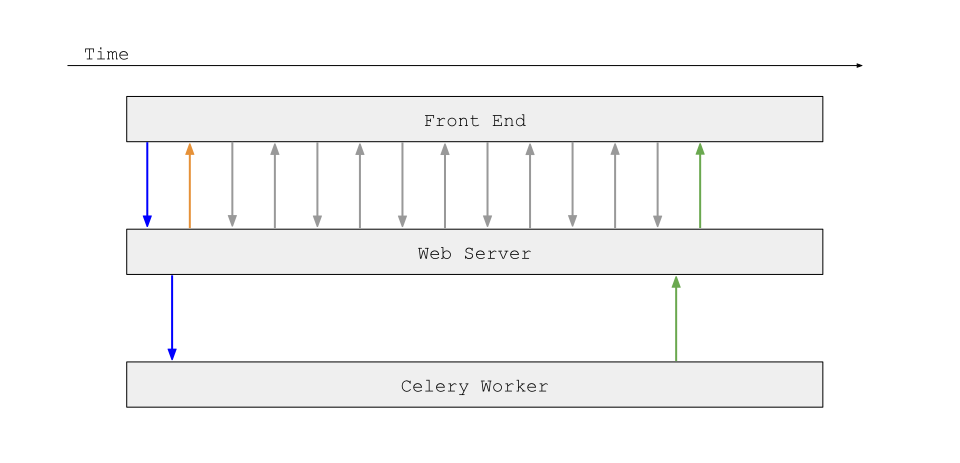
The overall interaction from the client’s perspective looks like this:
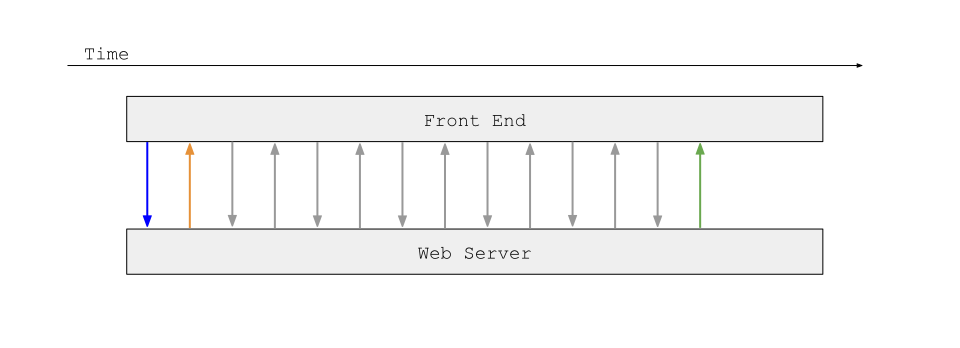
The blue arrow represents sending initial input, the orange arrow represents getting back a job id, the grey arrows represent polling for said job id, and the green arrow represents getting final results back.
However, if we let the web server do all the processing in addition to handling requests, it will overload and not be able to serve many clients. Thus, we add asynchrony on the back-end as well.
Python Asynchrony on the Back-End using Celery
When starting a new job, each endpoint defines its own Celery workflow as a task_list, and then hands it to a start_celery_job method. The id of the last task in the chain is saved to the job in the database and also sent back to the client. The client then uses this job id to poll for results, which is handled by a simple get_job endpoint
Thus the interaction now looks like:
Celery provides nice APIs for waiting for tasks, retries, message routing, and error handling. Tasks are triggered by messages sent by the broker. Retries are handled by a simple decorator. Routing can be specified using exchange and routing_key parameters which ensure that subsequent tasks execute on the same worker in case they depend on external state not passed explicitly between tasks. Error handling is accomplished using the link_error parameter, which when added to a task chain will capture any exception raised by a constituent task.
The workflows themselves can have tasks that execute in series (using Celery chains) or in parallel (using Celery groups). A chain is a simple linear sequence of tasks, each of which depends on the previous one. An example of a chain is how we analyze land cover usage for a given area of interest:
@decorators.api_view(['POST'])
@decorators.permission_classes((AllowAny, ))
def start_analyze(request, format=None):
user = request.user if request.user.is_authenticated() else None
area_of_interest = request.POST['area_of_interest']
routing_key = choose_worker()
return start_celery_job([
tasks.start_histogram_job.s(area_of_interest)
.set(routing_key=routing_key),
tasks.get_histogram_job_results.s()
.set(routing_key=routing_key),
tasks.histogram_to_survey.s(area_of_interest)
], area_of_interest, user)
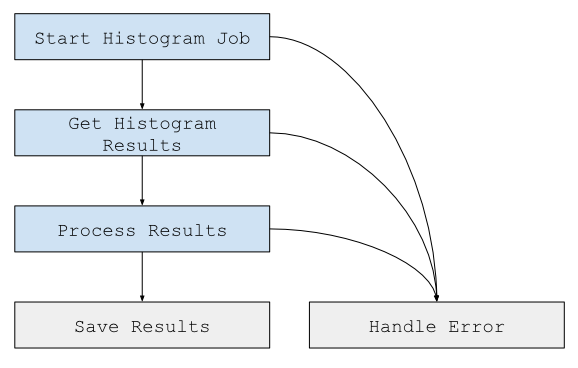
There are three tasks in this chain:
- Start a histogram geoprocessing job that for the given area of interest will return a count of the number of cells of each land cover type in the underlying raster.
- Get the job’s results.
- Translate the results into a format expected by the front-end.
Each task depends on the successful completion of the previous one. We specify a routing_key for start_histogram_job and get_histogram_job_results because they must occur on the same worker, since they must both access the same external geoprocessing service. Other tasks (such as histogram_to_survey, and save_job_results and save_job_error inside start_celery_job) only depend on the output from the previous task, thus need not be pinned to a specific worker. The workflow can be visualized as thus:
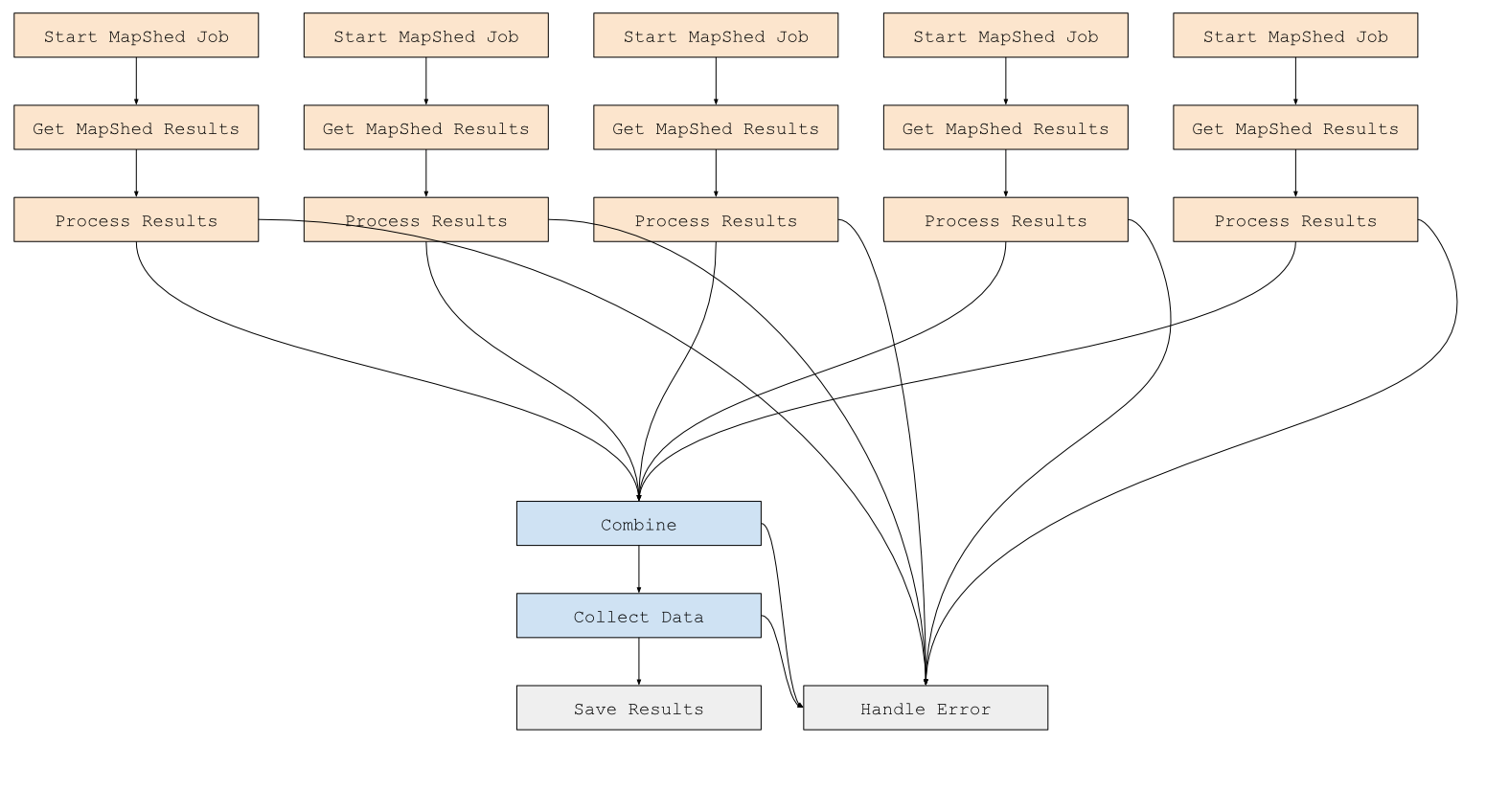
MapShed is an example of a more complex Celery workflow, that includes groups and chords. A group is a set of Celery tasks that is executed in parallel. A chord is a group followed by a callback that is fired when all the tasks in the group complete successfully. The workflow is to gather data in parallel from a number of different datasets, then combine and process them:
def geop_tasks(geom, routing_key):
# List of tuples of (opname, data, callback) for each geop task
definitions = [
('nlcd_streams', {'polygon': [geom.geojson], 'vector': streams(geom)}, nlcd_streams),
('nlcd_soils', {'polygon': [geom.geojson]}, nlcd_soils),
('gwn', {'polygon': [geom.geojson]}, gwn),
('avg_awc', {'polygon': [geom.geojson]}, avg_awc),
('nlcd_slope', {'polygon': [geom.geojson]}, nlcd_slope),
('slope', {'polygon': [geom.geojson]}, slope),
('nlcd_kfactor', {'polygon': [geom.geojson]}, nlcd_kfactor)
]
return [(mapshed_start.s(opname, data).set(routing_key=routing_key) |
mapshed_finish.s().set(routing_key=routing_key) |
callback.s())
for (opname, data, callback) in definitions]
@decorators.api_view(['POST'])
@decorators.permission_classes((AllowAny, ))
def start_mapshed(request, format=None):
user = request.user if request.user.is_authenticated() else None
area_of_interest = request.POST['area_of_interest']
geom = GEOSGeometry(area_of_interest, srid=4326)
routing_key = choose_worker()
return start_celery_job([
group(geop_tasks(geom, routing_key)),
combine.s(),
collect_data.s(geom.geojson)
], area_of_interest, user)
Here geop_tasks takes a geometry and a routing_key, and runs a number of geoprocessing chains in parallel. Each chain has three steps, akin to the analyze chain above:
- Start a MapShed data gathering geoprocessing job, that given an area of interest and a set of rasters, will return a grouped count of each combination of raster values.
- Get the job’s results.
- Translate results into a format usable by the next step.
Next we combine the results of each chain into a single dict, which is then passed to collect_data along with the area of interest, which merges these results with those from vector datasets stored in a database, whose final results are saved and returned to the client. The workflow can be visualized as so:
Since now we also take the geoprocessing service into account, our network diagram should now look like this:
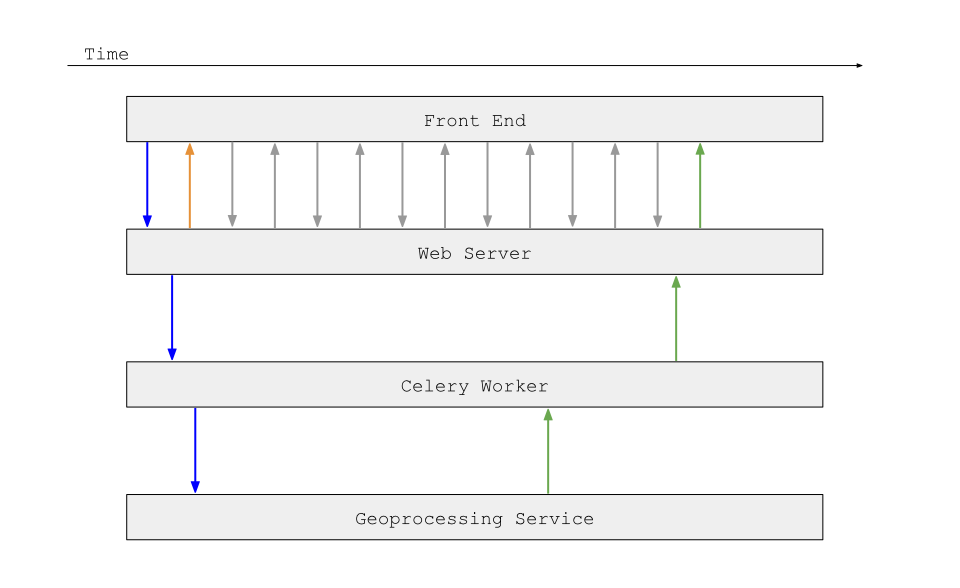
However, that’s not quite right. Often times, the geoprocessing step in a Celery chain is by far the longest, and it would be inefficient to let it block an entire worker. You may have noticed that for each geoprocessing task in the above workflows, we had two Celery tasks: a start and a get or finish. That’s because our geoprocessing service is asynchronous as well.
Asynchronous Geoprocessing using GeoTrellis and Spark JobServer
GeoTrellis is a high-performance geographic data processing engine that does all of the raster processing for Model My Watershed. It is made available to the main app as a web service, built on Spark JobServer (SJS). SJS offers a similar workflow as the one described above in Celery, comprised of an initial request with a payload which results in a job id, and then polling that job id until results are available.
To create an SJS job, we extend SparkJob, and implement the two compulsory methods:
object MapshedJob extends SparkJob {
override def validate(sc: SparkContext, config: Config): SparkJobValidation =
SparkJobValid
override def runJob(sc: SparkContext, config: Config): Any = {
config.getString("input.operationType") match {
case "RasterLinesJoin" => ...
case "RasterGroupedCount" => ...
case "RasterGroupedAverage" => ...
case _ => throw new Exception("Unknown Job Type")
}
}
}
where RasterLinesJoin, RasterGroupedCount, and RasterGroupedAverage are kinds of operations that could be called on the geoprocessing service. Since this is an internal service where we have perfect control over the environment, we assume that incoming configuration is aways valid.
The interaction would look like:
- Send GeoJSON and raster configuration to geoprocessing service
- Poll for given job id …
- … until results are received
Now we have a complete picture of all network calls in our system:
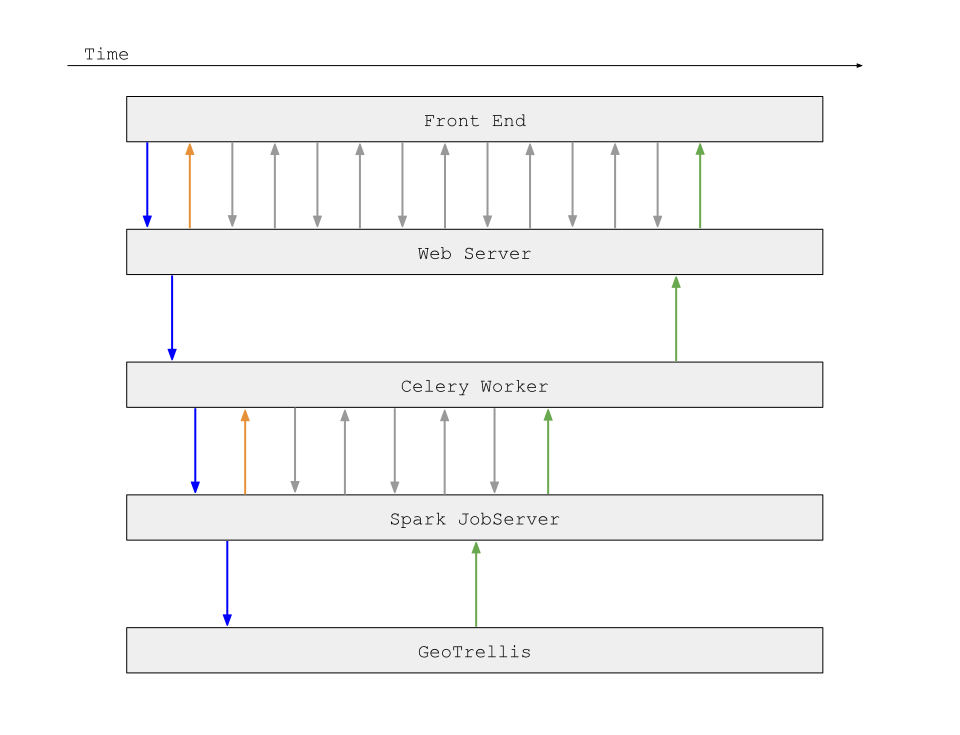
Implementation Details and Gotchas
Dynamic Celery Task Chains
To further optimize processing, in some cases the front-end caches calculated values and reuses them. For example, the TR-55 Site Storm Model takes three inputs: the area of interest, shapes of any drawn modifications (such as land cover or conservation practices), and a scalar input (precipitation level). The first two require raster geoprocessing before they can be used by the model, while the final one can be used immediately. To speed up user interaction, we cache the results of geoprocessing the area of interest and the modifications, and run those calculations again only if the inputs have changed. This leads to three possible Celery workflows:
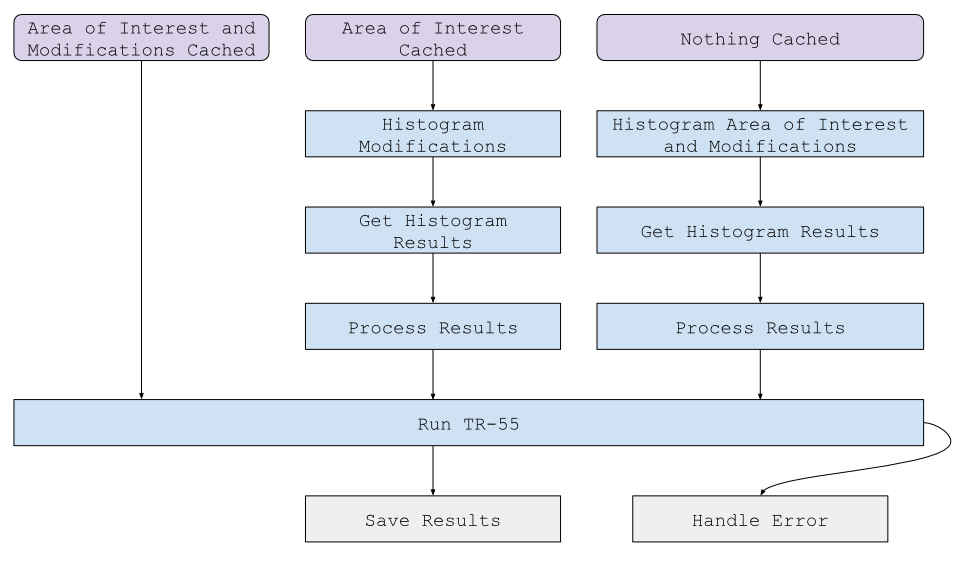
Celery does not natively support conditional or dynamic task chains. We got around this by creating a list of tasks depending on input, and converting it to a Celery chain at the very end.
Antepenultimate Celery Chords
Due to a bug in Celery v3.1.23 (the production release as of this writing), a chord cannot be the penultimate task in a chain. A Celery chord is a pair of a group (list of tasks executed in parallel) and a callback that is executed when all the tasks in the group complete successfully. In the MapShed workflow, the group (consisting of orange tasks) and combine together form a chord:
While the combine and collect_data tasks could be merged into one, that would have made a chord the penultimate task in the chain, whose reference would be returned instead of the final task save_job_results. We worked around this by splitting the chord’s callback in two.
Error Handling in Nested Chains
Even though the MapShed workflow shown above is complex with multiple specialized tasks, the error handling is very general. Regardless of the task that raises an exception or encounters an error, we simply want to log it to the database and return to the client. We assumed that given its general applicability, we could specify the error handler once on the parent chain and have it be catch errors raised anywhere in the constituent tasks. Unfortunately this is not true, and we must attach the error handler separately to every task in every subchain. We do this by defining the error handling task once, and passing it as a parameter to the function that creates all geoprocessing task chains.
Infinite Chord Unlocks
Celery implements chords using a special chord_unlock task under the hood which repeatedly checks to see if all the tasks in its group have completed or not. If not, it continues retrying infinitely until they do, signified by the hard-coded, unconfigurable max_retries=None default value. For the most part this works fine as the tasks either complete successfully or fail.
However, for our MapShed workflow we use a group of chains, not a group of tasks. Since each chain returns the reference of the final task in the chain, chord_unlock tests to see only if the final task in the chain has completed. In case there is an error in any of the non-final tasks of the chain, the final task will never be executed at all, which results in chord_unlock being called an infinite amount of times.
Our strategy to address this was twofold: firstly we capture all exceptions in all non-final tasks in the chain and instead of raising them, pass them on to the next task as output. Each task checks if it receives an error, and if so passes it along immediately. If the final task receives an error, it raises an exception.
Secondly, even though the above should take care of all foreseeable errors, in order to make our application more robust we wrote a custom version of chord_unlock to patch into Celery on application start. The code is identical except for the new configuration parameter CELERY_CHORD_UNLOCK_MAX_RETRIES which ensures that our running application does not get stuck in an infinite loop.
Celery Retries as Exceptions
Celery implements retries as an exception, to indicate to the worker that the current task should exit immediately and be rescheduled. Unfortunately, when we started capturing all exceptions for handling exceptions in chains above, we also captured the retry exceptions and broke the retry functionality. This was fixed by capturing retry separately and simply re-raising it.
Active Stack Task Routing
Our deployment stack consists of a load balancer, a number of App VMs that handle web requests, a number of Worker VMs each running two Celery workers and an instance of SJS, and a number of cloud services on AWS. All Worker VMs share the same redis instance for brokering messages between various Celery workers. We use the blue-green deployment strategy for pushing builds to production. Assuming the current active stack is blue, we will spin up a new green stack of all the VMs, test it while it is dark, switch over to it once testing has passed, and then spin down the blue stack once it is no longer being used.
We use the Celery routing_key parameter to ensure that geoprocessing calls go to the same instance of SJS, since we cannot start a job in one instance and query for it in another. Other tasks can be routed to any available worker, and thus don’t necessarily need to be routed explicitly. And in most cases this works correctly.
However, during deployment there are two stacks of Worker VMs, and thus Celery workers, that all share the same redis broker. This could lead to tasks from the newly spun dark stack to leak to production workers, clogging them up and reducing production capacity, but also leaking production tasks to workers in the dark stack, which may expect data in a different format and cause errors in production! To prevent this we explicitly route all tasks with a choose_worker method that gets a list of active workers in the current stack.
Conclusion
Making a large system asynchronous can be complex and have a number of side-effects that need to be addressed. It often times requires touching the entire stack from top to bottom, and thus needs solutions at every stage. Scaling out is much easier if a system is designed to be so from the beginning. When done right, the user experience is also significantly better.
The code for Model My Watershed is available on GitHub where all development happens in the open. Feel free to browse to find the actual implementation, which covers all edge cases and runs in production.
Have you worked with Celery, or Spark JobServer, or asynchronous web applications?
Share your experiences with us on Twitter @azavea.