
The initial public release of Raster Vision (0.8) almost two years ago enabled us and other groups to run end-to-end deep learning workflows on earth observation data. Over time, we added new features and bug fixes, but found that it was difficult to add certain features and to customize workflows for idiosyncratic projects — which is most of them. We concluded that the only way to fix this was to refactor the codebase from the ground up to make it simpler, more consistent, and more flexible. This latest release of Raster Vision aims to accomplish this, along with many other improvements. Below are some of the main changes in this release. For a full list of changes, please see the official change log.
Simplified configuration schemas
We are still using a modular, programmatic approach to configuration, but have switched to using a Config base class which uses the Pydantic library. This allows us to define configuration schemas in a declarative fashion, and let the underlying library handle serialization, deserialization, and validation. In addition, this has allowed us to DRY up the configuration code, eliminate the use of Protobufs, and represent configuration from plugins in the same fashion as built-in functionality. To see the difference, compare the configuration code for ChipClassificationLabelSource in 0.11 (label_source.proto and chip_classification_label_source_config.py), and in 0.12 (chip_classification_label_source_config.py).
Abstracted out pipelines
Raster Vision includes functionality for running computational pipelines in local and remote environments, but previously, this functionality was tightly coupled with the “domain logic” of machine learning on earth observation data in the Experiment abstraction. This made it more difficult to add and modify commands, as well as use this functionality in other projects. In this release, we factored out the experiment running code into a separate rastervision.pipeline package, which contains a Pipeline class and can be used for defining, configuring, customizing, and running sequences of commands in parallel and using a mixture of CPUs and GPUs.
Reorganization into plugins
The rest of Raster Vision is now written as a set of optional plugins that have Pipelines which implement the “domain logic” of machine learning on geospatial data. Implementing everything as optional (pip installable) plugins makes it easier to install subsets of Raster Vision functionality, eliminates separate code paths for built-in and plugin functionality, and provides (de facto) examples of how to write plugins. The figure below shows the packages, the dependencies between them, and important base classes within each package.
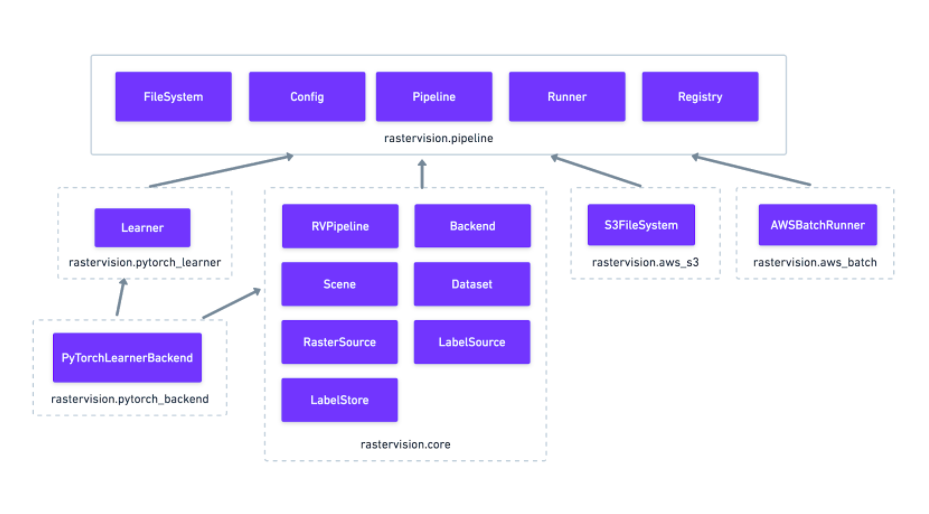
More flexible PyTorch backends
Our previous 0.10 release added backends using PyTorch and torchvision for chip classification, semantic segmentation, and object detection. In this release, we removed the Tensorflow backends and abstracted out the common code for training models into a flexible Learner base class with subclasses for each of the computer vision tasks. This code is in the rastervision.pytorch_learner plugin, and is used by the Backends in rastervision.pytorch_backend. By decoupling Backends and Learners, it is now easier to write arbitrary Pipelines and new Backends that reuse the core model training code, which can be customized by overriding methods such as build_model.
Future work
In the future, we plan on adding the ability to read and write datasets in STAC format using the label extension. This will facilitate integration with other tools such as Azavea’s GroundWork labeling app. We also plan on adding the ability to train models on multi-band imagery, rather than having to pick a subset of three bands. The fact that our Backends now share most of their code, and directly use the torch and torchvision libraries without any other intermediaries will make implementing this feature much easier.